Colossal-AI 框架技术解读
April 11, 2023
本文基于如下论文对 Colossal-AI 框架技术进行解读,由于原论文对于优化策略的描述较为简略,为方便理解,笔者自行查阅了相关论文并对相关工作的核心思想和流程进行了概括。随着框架的迭代更新,一些新的特性不在本文的讨论范围内,可以自行查阅官方文档。
- Li, Shenggui, et al. “Colossal-AI: A unified deep learning system for large-scale parallel training.” arXiv preprint arXiv:2110.14883 (2021).
Abstract
The success of Transformer models has pushed the deep learning model scale to billions of parameters. Due to the limited memory resource of a single GPU, However, the best practice for choosing the optimal parallel strategy is still lacking, since it requires domain expertise in both deep learning and parallel computing. The Colossal-AI system addressed the above challenge by introducing a unified interface to scale your sequential code of model training to distributed environments. It supports parallel training methods such as data, pipeline, tensor and sequence parallelism, as well as heterogeneous training methods intergrated with zero redundancy optimizer. Compared to the baseline system, Colossal-AI can achieve up to 2.76 times training speedup on large-scale models.
背景介绍
随着近年来人工智能模型参数量的爆炸式增长,GPU 等深度学习加速器的有限内存已成为大模型发展的瓶颈,为了减少 GPU 上的内存占用,研究人员们提出了很多方法,目前最先进以及最受欢迎的系统解决方案是 Megatron-LM 和 DeepSpeed,其中,Megatron-LM 主要是通过流水线并行和张量并行来对 Transformer-based 模型的训练进行优化,DeepSpeed 则是通过有效划分与模型相关的数据来消除数据并行训练中的内存冗余。对于框架使用者来说,最理想的解决方案是仅需通过简短的代码修改即可将先进的优化策略引入到原有的模型训练过程中,然而 Megatron-LM 上手使用的成本较高,DeepSpeed 只提供了数据并行方案并且需要与 Megatron-LM 进行集成来实现混合并行,且 DeepSpeed 的实现较为复杂,系统的性能和扩展性较差。为了解决上述问题,HPC-AI 团队开发了 Colossal-AI,通过在一个深度学习系统中集成一系列的训练加速技术并通过提供用户友好的 API 使分布式训练变得简单,同时允许用户保持原有程序的编码习惯。
相关技术
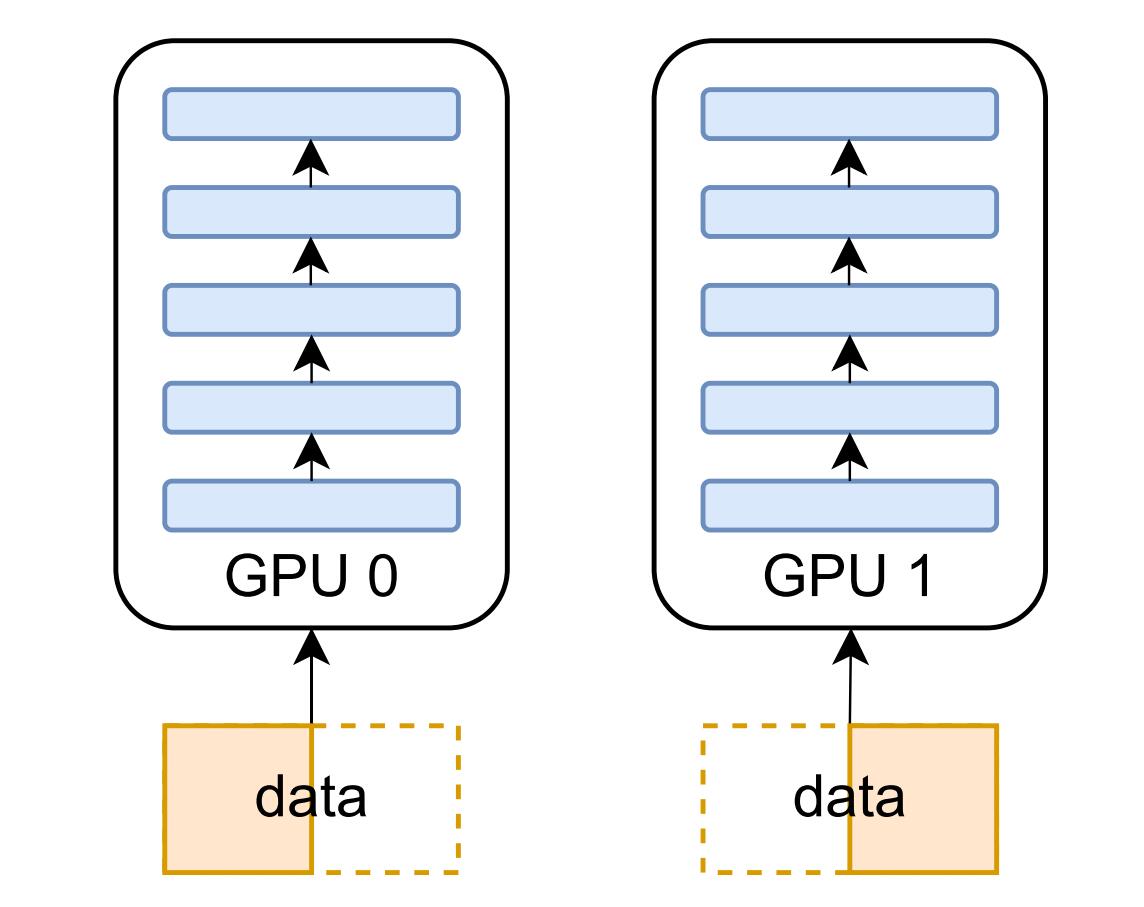
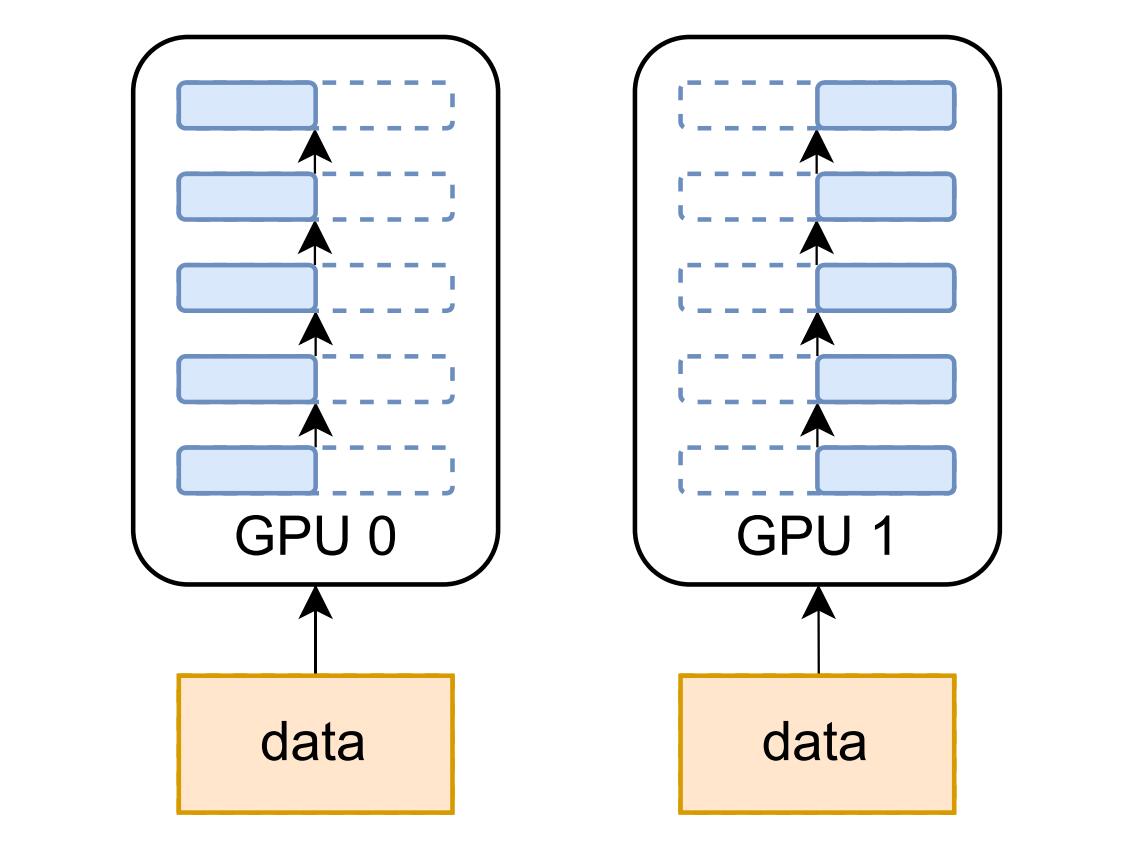
数据并行
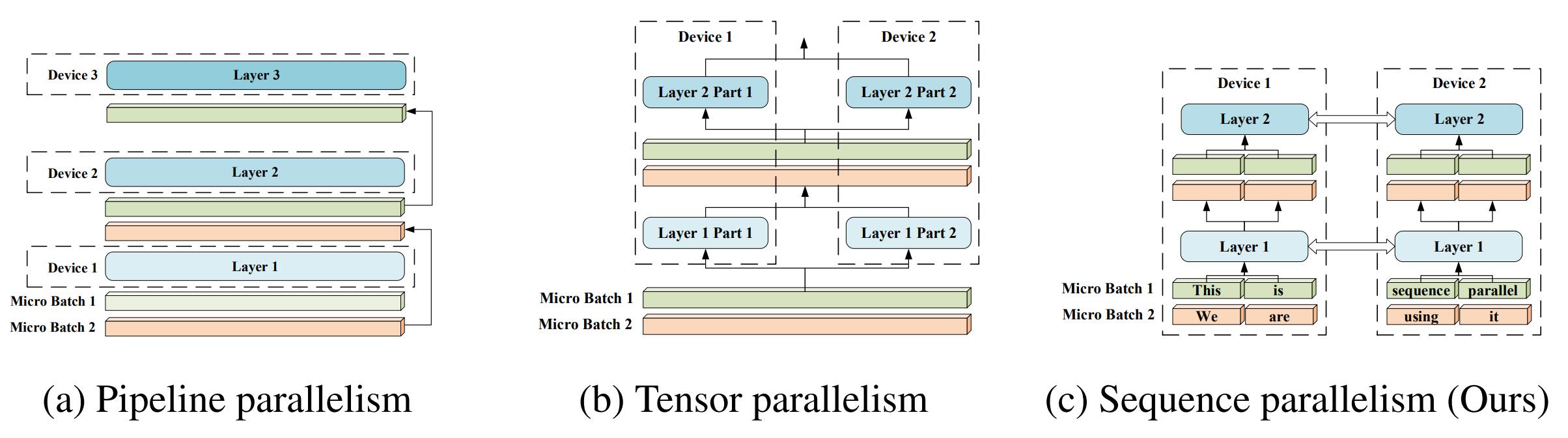
由于其简单性,数据并行是最常见的并行形式。在数据并行训练中,模型被跨设备复制,数据集被分成几个碎片,每个数据集分片都分配给一个设备并提供给相应设备上的模型。由于每个设备都有完整的参数集,因此在训练过程中各设备需要以通信的方式来同步模型权重,在反向传播过程中,优化器将使用同步梯度更新参数。在数据并行训练中,每个 GPU 都持有整个模型权重的副本,当模型的规模增加时,GPU 的内存将成为瓶颈,为解决此问题,模型并行被提出,其对模型参数进行分片使得每个设备只需持有部分模型权重,模型并行包括张量并行、流水线并行、序列并行,下文将逐一进行讲解。
张量并行
参考:https://colossalai.org/zh-Hans/docs/features
张量并行将张量分片到一组设备上,需要分布式矩阵-矩阵乘法算法进行算术计算。
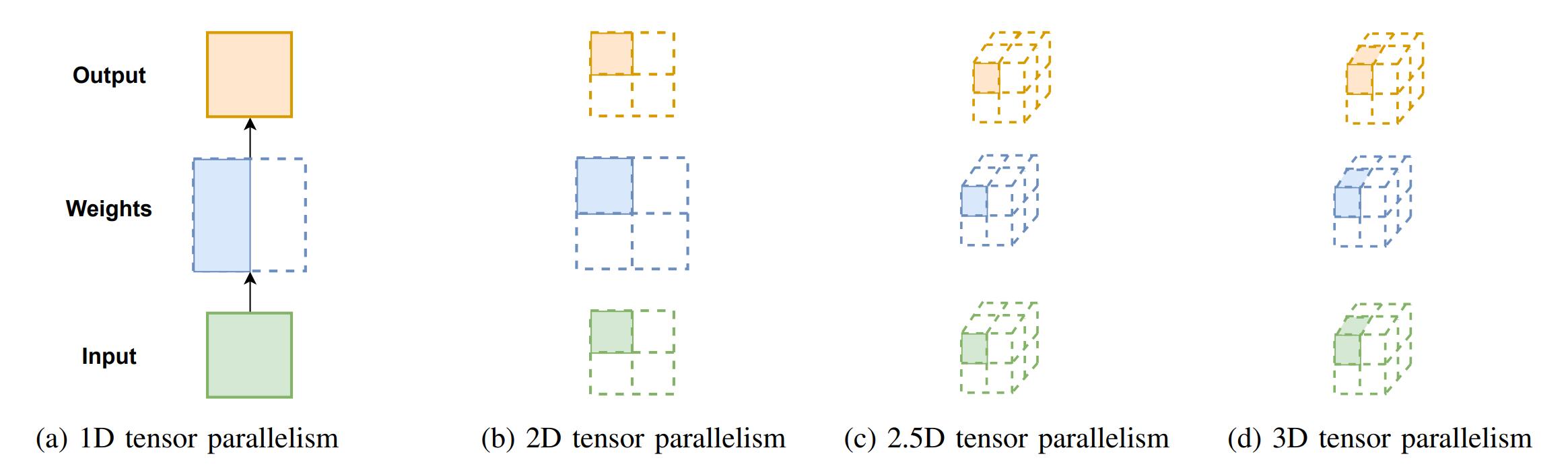
1D 张量并行
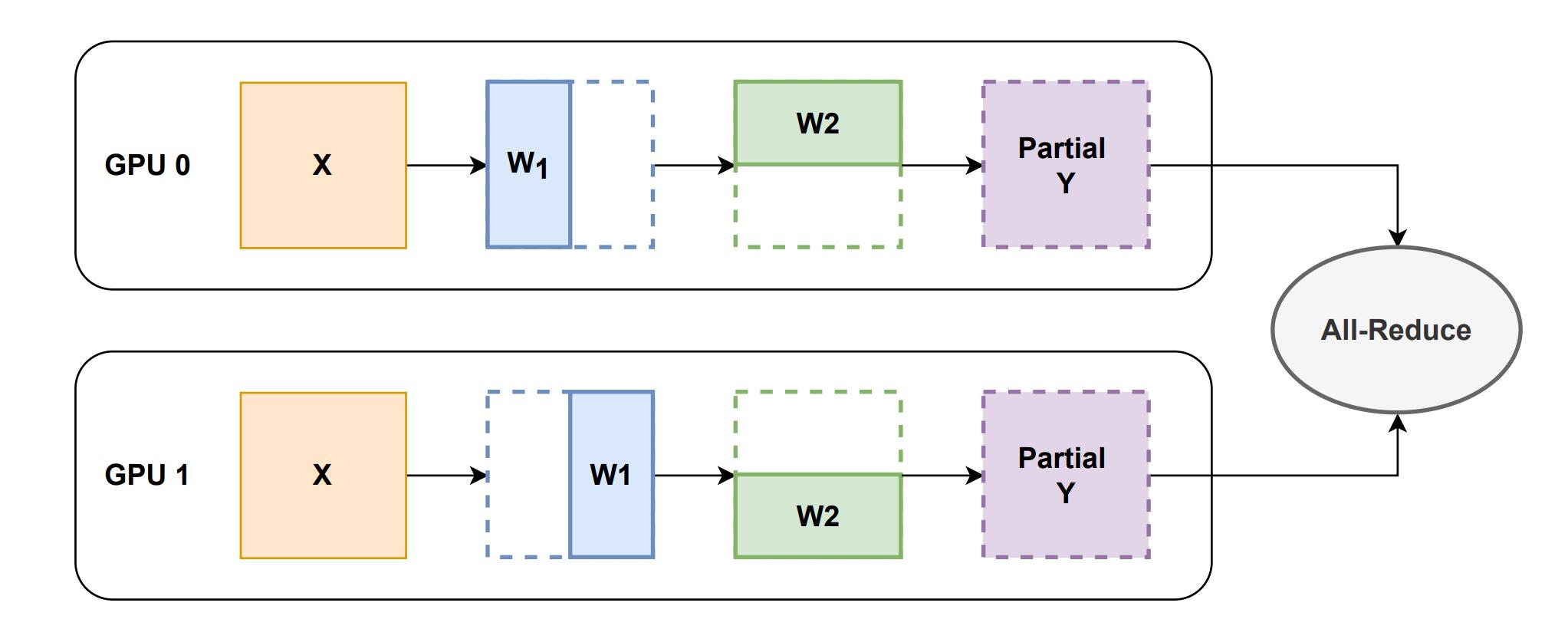
Megatron-LM 提出了一维张量并行,其在 Transformer 架构的行或列维度上拆分线性层。以 MLP 模块为例,一维张量并行对线性层权重进行划分,以分布式的方式在单个设备上计算得到输出的部分结果,然后应用 All-Reduce 集合通信来获得该矩阵乘法的最终结果。
优点:
- 若有个设备参与训练,则每个设备将持有的模型参数,这使得模型的大小可以随着设备数量的增加而扩大,从而突破了单一设备内存容量的限制。
缺点:
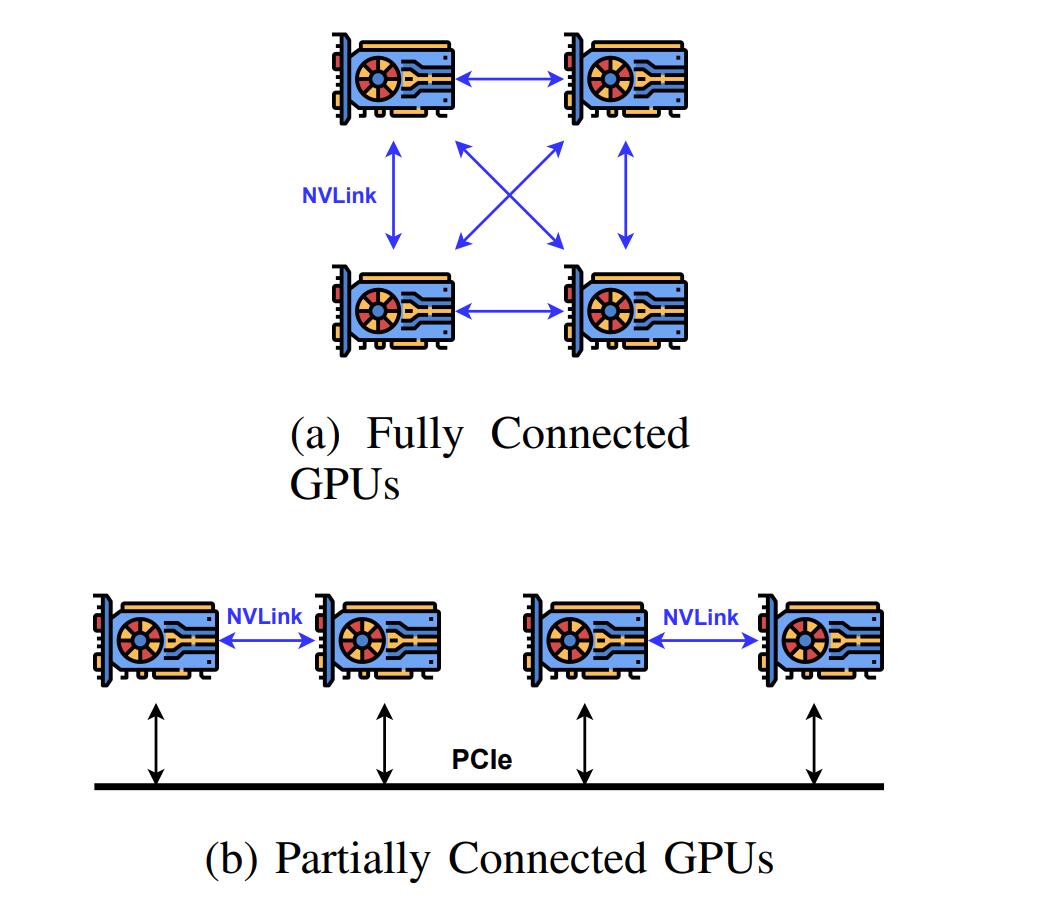
- 集合通信的开销受设备的影响较大。通过 NVLink 全连接的设备之间的通信带宽非常高,但是由于硬件成本问题,大多数设备只有部分连接的 NVLink,远程设备之间通过 PCIe 总线进行通信,通信带宽较低,阻碍了 All-Reduce 操作的效率。
- 输入和输出中存在冗余的内存使用。以 MLP 层为例,其输入和输出在不同设备上是重复的,这种内存冗余限制了在有限的硬件资源上可以训练的最大模型规模。
2D 张量并行
一维张量并行并没有对各层的输出进行划分,存在着大量的内存冗余,为了平均分配计算和内存负荷,二维张量并行被提出,其依赖于 SUMMA 矩阵乘法算法,并沿两个不同的维度拆分输入数据、模型权重以及层输出。
以线性层为例,给定个设备,张量被分成个块,每个块由一个 GPU 拥有,GPU 以方形网络拓扑排列,一共有行,每行有个 GPU。计算过程包括步,初始时,输入和权重的划分情况如下:
第一步,在其行中被广播,在其列中被广播,然后在每个处理器上将和相乘:
第二步,在其行中被广播,在其列中被广播,然后在每个处理器上将和相乘:
最后相加得:
二维张量并行使得输入和输出的存储不再冗余,相比一维张量并行,降低了很多内存消耗。部分输入和权重通过广播在设备之间进行通信,尽管二维张量并行相比一维张量并行对模型权重有额外的通信开销,但由于其更精细的分区方案,当设备数较多时,通信传输的数据量往往更少。
2.5D 张量并行
2.5D 张量并行引入了可选的这一维度,当是,其接近于 2D 张量并行,当时,其对矩阵进行了三次划分并增加了一个并行度。给定个设备,张量以的形式被划分,其中是方形拓扑的宽度大小,是可选的,当扩展到大量设备时,2.5D 张量并行将比 2D 张量并行更有效,因为它进一步减少了通信量。
以线性层为例,给定个设备,其中,首先将输入划分为行,列:
其可被重塑为层:
权重的划分为:
然后对于的每一层,应用与上述 2D 张量并行中相同的 SUMMA 算法与相乘。
3D 张量并行
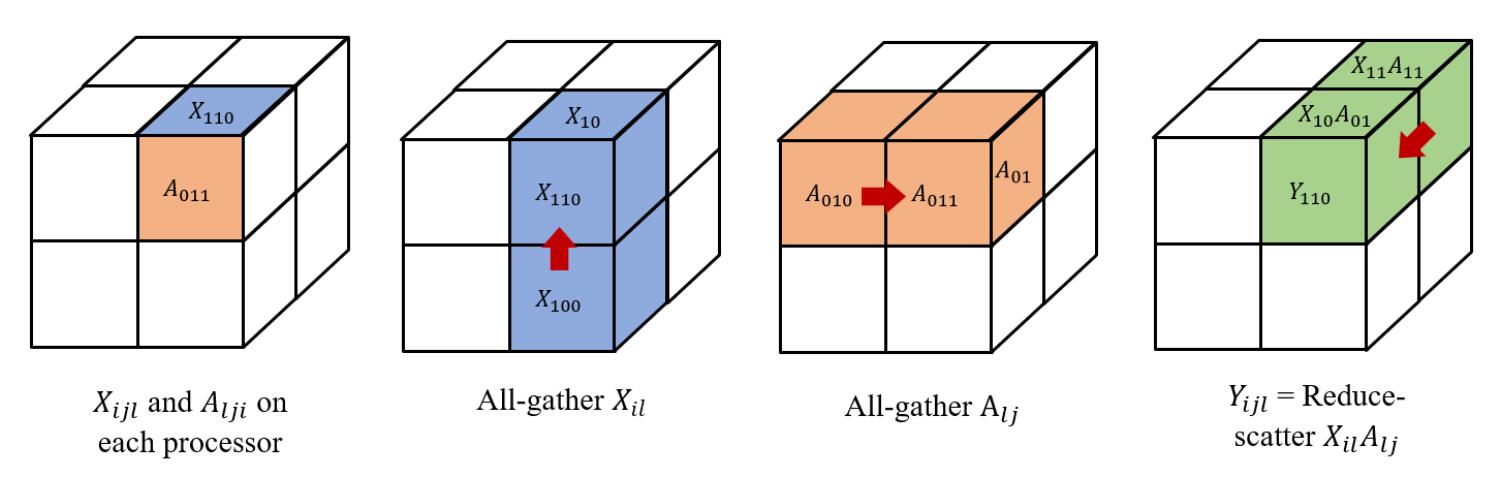
3D 张量并行以立方体的方式来划分张量,由于不是每个张量都有 3 个维度,因此选择仅对第一个和最后一个维度进行分区,其中第一个维度将被划分两次。
以线性层 为例,给定 个设备,其中 , 和 被划分为:
其中, 和 被存储在设备 上,计算过程如下图所示:
讨论
张量并行方法的选择依赖于 GPU 的数量,1D 方法适用于任何数量的 GPU,而 2D, 2.5D, 3D 方法分别需要 , , 数量的 GPU。2D, 2.5D, 3D 张量并行与 1D 张量并行相比,在扩展到大量设备时可以提供更低的通信开销,此外,它们与流水线并行具有更好的兼容性,因为 1D 张量并行在流水线阶段之间存在着许多额外的通信开销。在 1D 张量并行中,为了节省跨节点通信带宽,张量被分成块来进行传递,并且在到达目标流水线阶段后需要进行 All-gather 操作。而在高级张量并行方法中,传递到下一阶段的张量已经是整个逻辑张量的子块,因此不需要额外的拆分和聚合操作。
流水线并行
除张量并行外,另一种对模型进行划分的方案是按层拆分模型,与张量并行相比,流水线并行更加友好,因为它不需要改变层的计算流程。
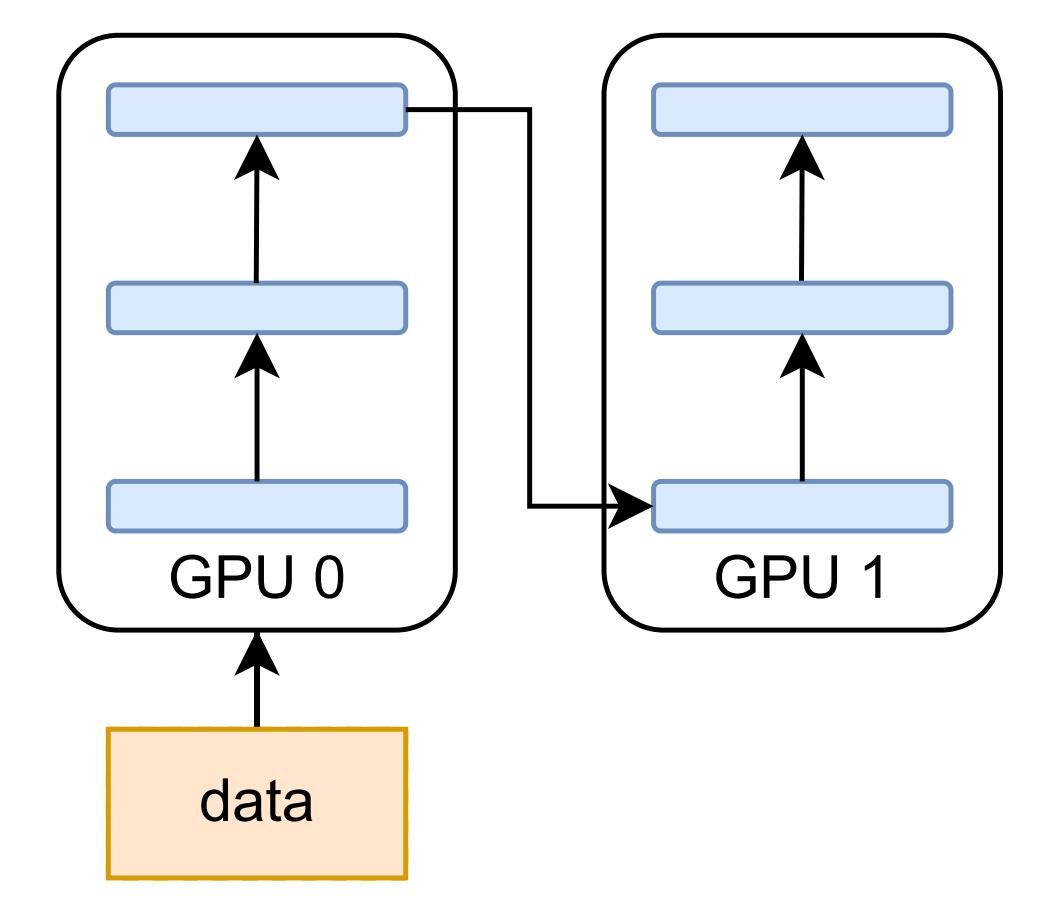
一个 batch 被划分为更小的 micro-batch,然后在各 micro-batch 之间流水线式地执行。前向传播时,每个设备将中间激活传递到下一个阶段,并且只计算最后一个流水线阶段的损失值。后向传播时,每个设备将梯度传递回前一个流水线阶段,每个流水线阶段的参数的梯度被累积起来,只有当流水线的 micro-batch 数据处理完时,参数才会更新。
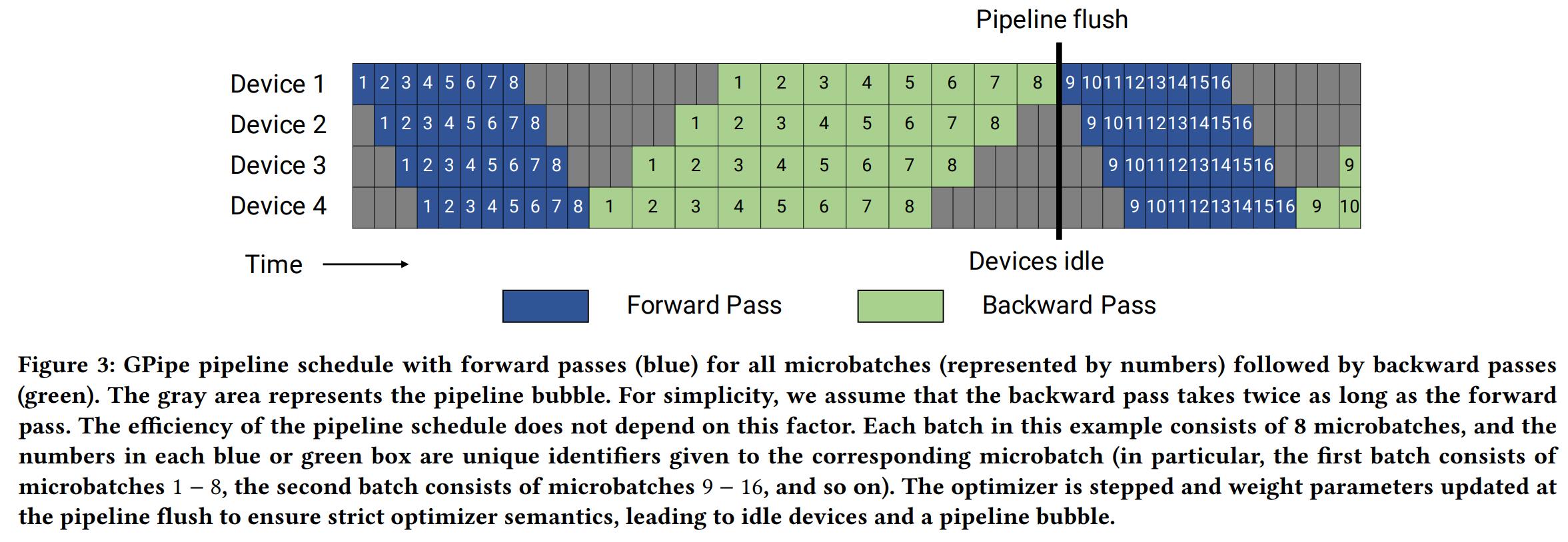
流水线并行允许多个设备同时计算,从而具有更高的�吞吐量,它还最大限度地减少了跨节点通信,因为只有激活和梯度在流水线阶段之间进行通信。其缺点是会存在一些 bubble time,即一些设备空闲而其他设备在进行计算,导致计算资源的浪费,GPipe 和 PipeDream 等工作针对这一问题进行了优化,Colossal-AI 使用了 Megatron-LM 中的 1F1B 流水线。
-
GPipe:执行完一个批次中所有微批次的前向传播后再执行所有微批次的后向传播。
-
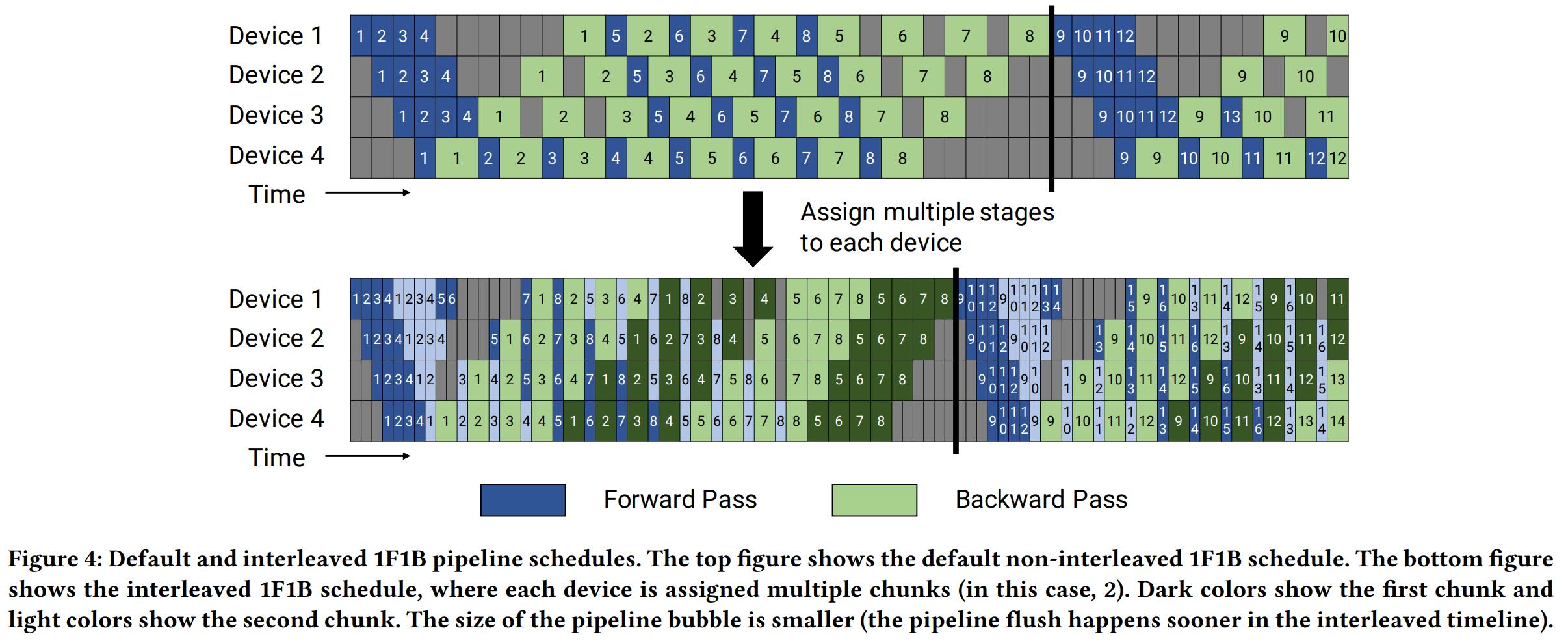
Non-interleaved 1F1B:
- 首先是 warm-up 阶段,设备执行不同数量的前向传播,直到有微批次可以进行反向传播
- 每个设备进入稳定状态,执行一次前向传播,然后执行一次后向传播
- 最后,在批次结束时,完成所有剩余微批次的反向传播
- 在该调度方案中,将 in-flight 的微批次的数量限制为流水线的深度,即未完成反向传播且需要维护激活值的微批次的数量最多为,相比之下,GPipe 所需存储的数量为一个批次中微批次的总数,因此当时,该方案更节省内存,然而,它需要和 GPipe 一样的时间来完成一轮计算。
-
Interleaved 1F1B:为了进一步缩短 bubble time,每个设备都可以对层的多个子集(称为模型块)执行计算,而不是对单个连续的层集进行计算。例如,如果每个设备之前有 4 层(即设备 1 有第 1-4 层,设备 2 有第 5-8 层,依此类推),我们可以让每个设备为两个模型块(每个有 2 层)执行计算,即设备 1 具有第 1、2、9、10 层;设备 2 有第 3、4、11、12 层;等等。通过这种方案,流水线��中的每个设备都被分配了多个流水线阶段,每个流水线阶段的计算量都比以前少。该方案要求一个批次中的微批次的数量是流水线并行程度(流水线中的设备数量)的整数倍。虽然该方案缩短了 bubble time,但是增加了额外的通信开销,原文章中讨论了如何利用多 GPU 服务器中的 InfiniBand 网卡来减少这种额外通信的影响。
- Reference:
- Narayanan, Deepak, et al. “Efficient large-scale language model training on gpu clusters using megatron-lm.” Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 2021.
序列并行
张量并行主要解决模型数据带来的内存瓶颈。然而,非模型数据可能会成为长序列输入任务的瓶颈。由于 Transformer 中的自注意力机制相对于序列长度具有二次复杂度,长序列数据会增加中间激活消耗的内存使用量,从而限制单台设备的训练能力。序列并行通过打破长序列维度带来的内存墙来解决这一问题,在该方法中,模型像数据并行一样被复制到各个设备上,然而,数据不是按批次维度分割,而是沿序列维度分割,每个设备只保留子序列。
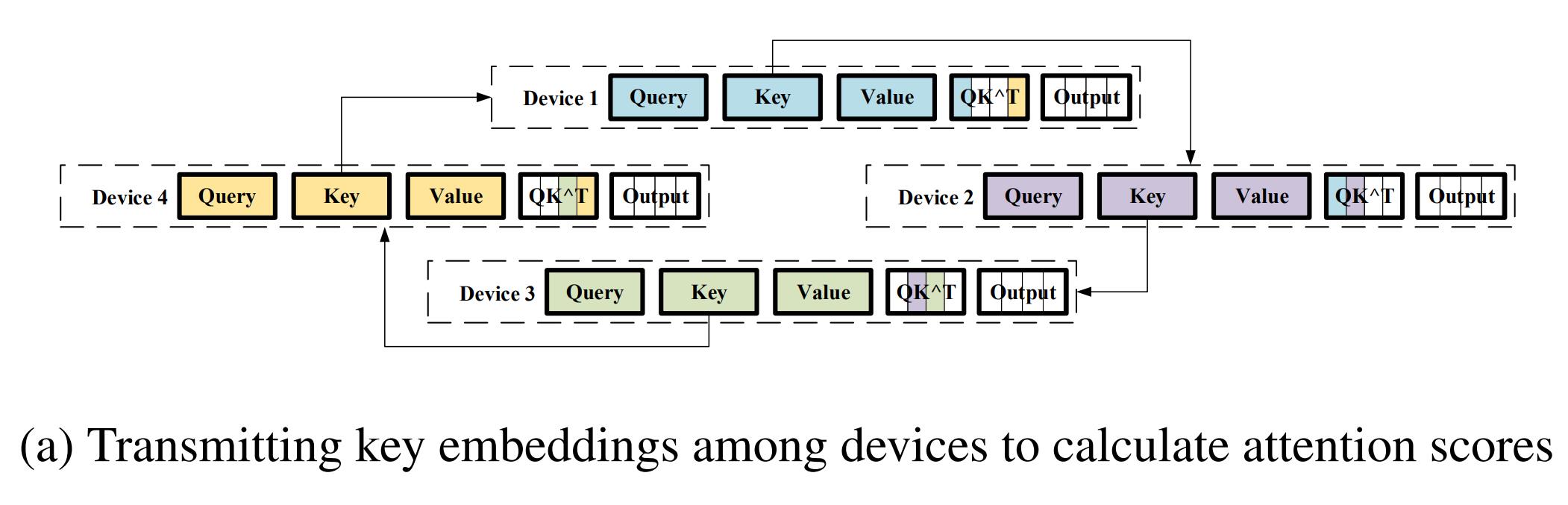
Ring Self-Attention:
-
符号定义:台设备,第台设备上的 query/key/value embedding 分别为, , ,embedding 的长度为,其中为原始序列长度。
-
计算目标:每台设备的注意力分数
-
阶段一:在各设备之间传递 key embedding 以环形的方式计算, 该通信需要执行次,以确保每个子序列的 query embedding 可以乘以所有的 key embedding。具体地,每个设备首先使用本地 key embedding 和 query embeding 来计算本地的部分结果,然后用收到的来自前一个设备的不同的 key embedding 来计算新的部分结果。
-
阶段二:同上,在各设备之间传递 value embedding,完成注意力分数的计算。
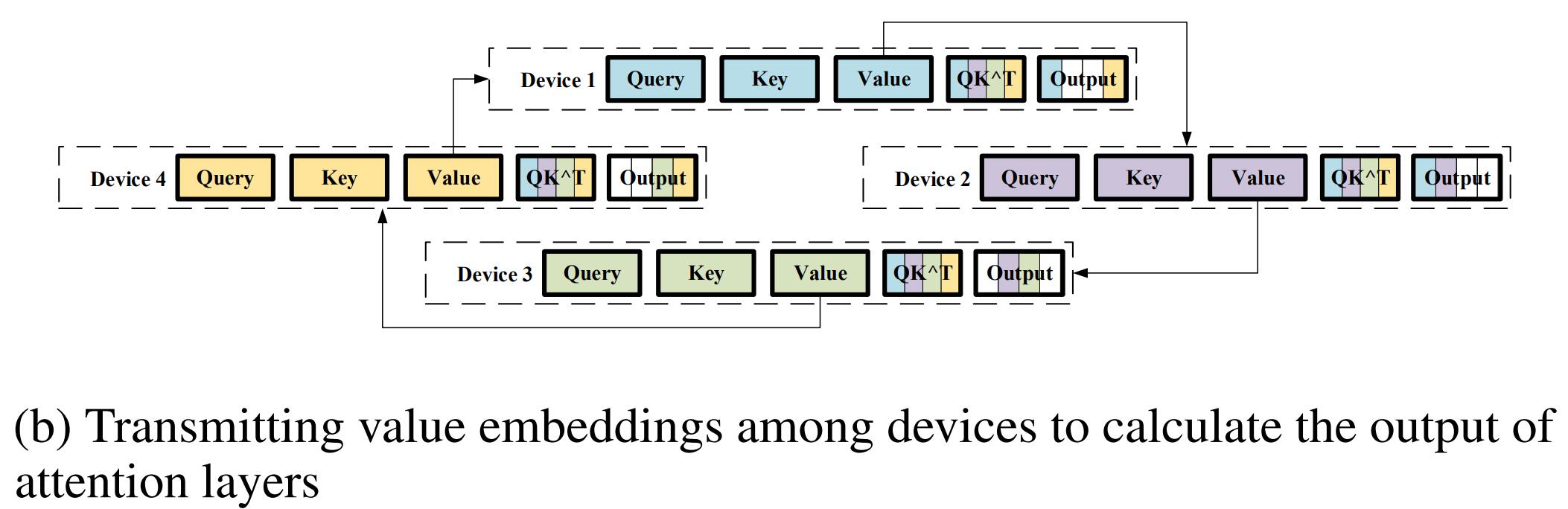
- Reference:
- Li, Shenggui, et al. “Sequence Parallelism: Long Sequence Training from System Perspective.” arXiv e-prints (2021): arXiv-2105.
零冗余数据并行
大模型常用的训练方法
混合精度训练
大模型通常需要更多的计算和内存资源来训练,BAIDU 和 NVIDIA 联合提出了混合精度训练,在尽可能减少模型精度损失的同时利用半精度浮点数来减少内存占用以及加速训练。该工作引入了三种技术来防止模型精度的损失:
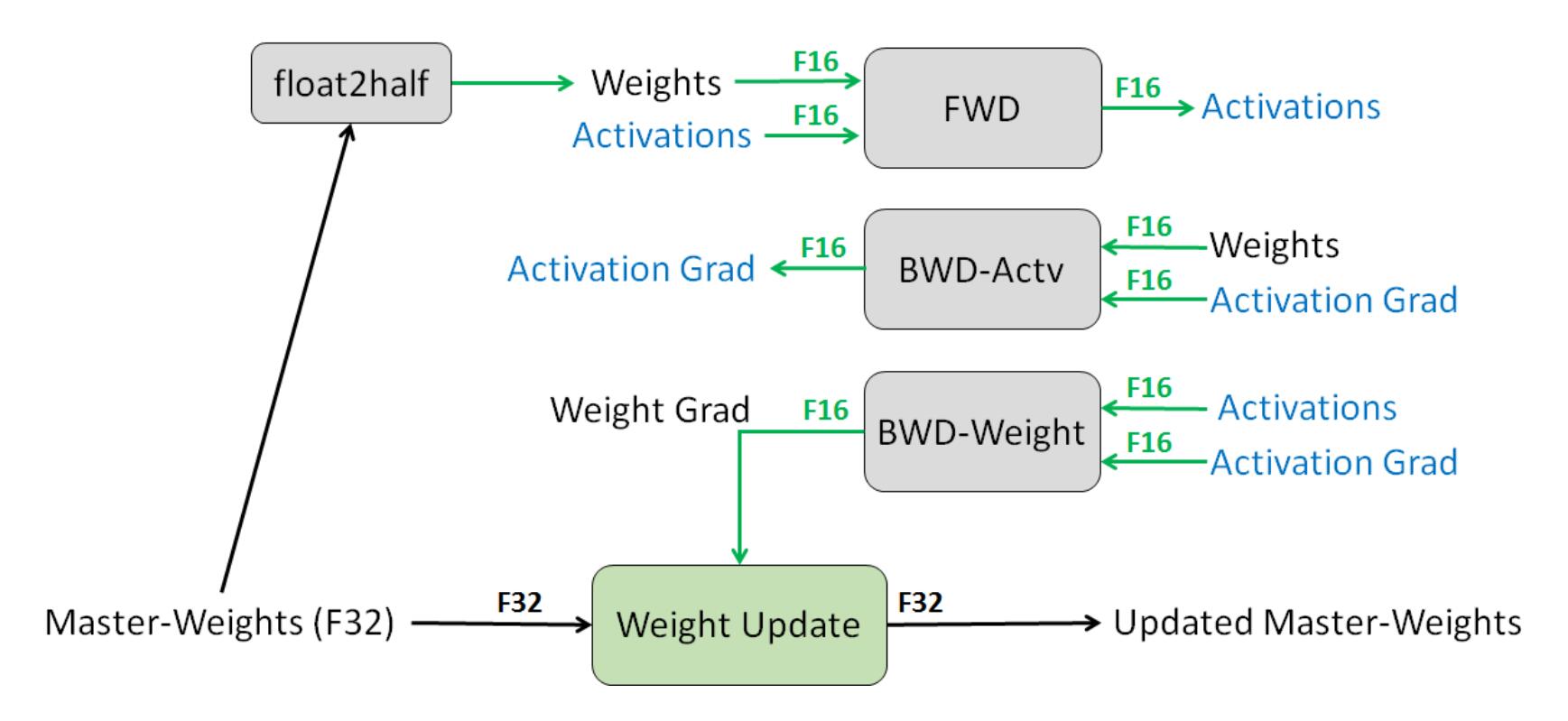
- FP32 Master Copy Of Weights:在混合精度训练中,权重、激活和梯度被存储为 FP16,训练时权重从 FP32 转成 FP16 进行前向计算,得到 loss 之后,用 FP16 计算梯度,再转成 FP32 更新到 FP32 的权重上
- Loss Scaling:很多激活值比较小,无法用 FP16 表示,需要进行梯度缩放,否则就会丢失为零。
- Arithmetic Precision:经过实验,作者发现将 FP16 的矩阵相乘后和 FP32 的矩阵进行加法运算,写入内存时再转回 FP16 可以获得较好的精度,英伟达 V 系列 GPU 卡中的 Tensor Core 支持这种操作。因此,在进行大型累加时(batch-norm、softmax),为防止溢出都需要用 FP32 进行计算,且加法主要被内存带宽限制,对运算速度不敏感,因此不会降低训练速度。另外,在进行 Point-wise 乘法时,用 FP16 或者 FP32 都可以。
Adam 优化器

显存占用分析
-
Model States (majority):the optimizer states (such as momentum and variances in Adam), gradients, and parameters
-
Residual States:activation, temporary buffers and unusable fragmented memory
ZeRO-DP
通过划分模型状态而不是复制它们来消除数据并行中 Model States 的冗余,并通过在训练期间使用动态通信来保持计算/通信效率。其中,Stage 1 和 Stage 2 没有增加通信量,Stage 3 的通信量会有所增加。
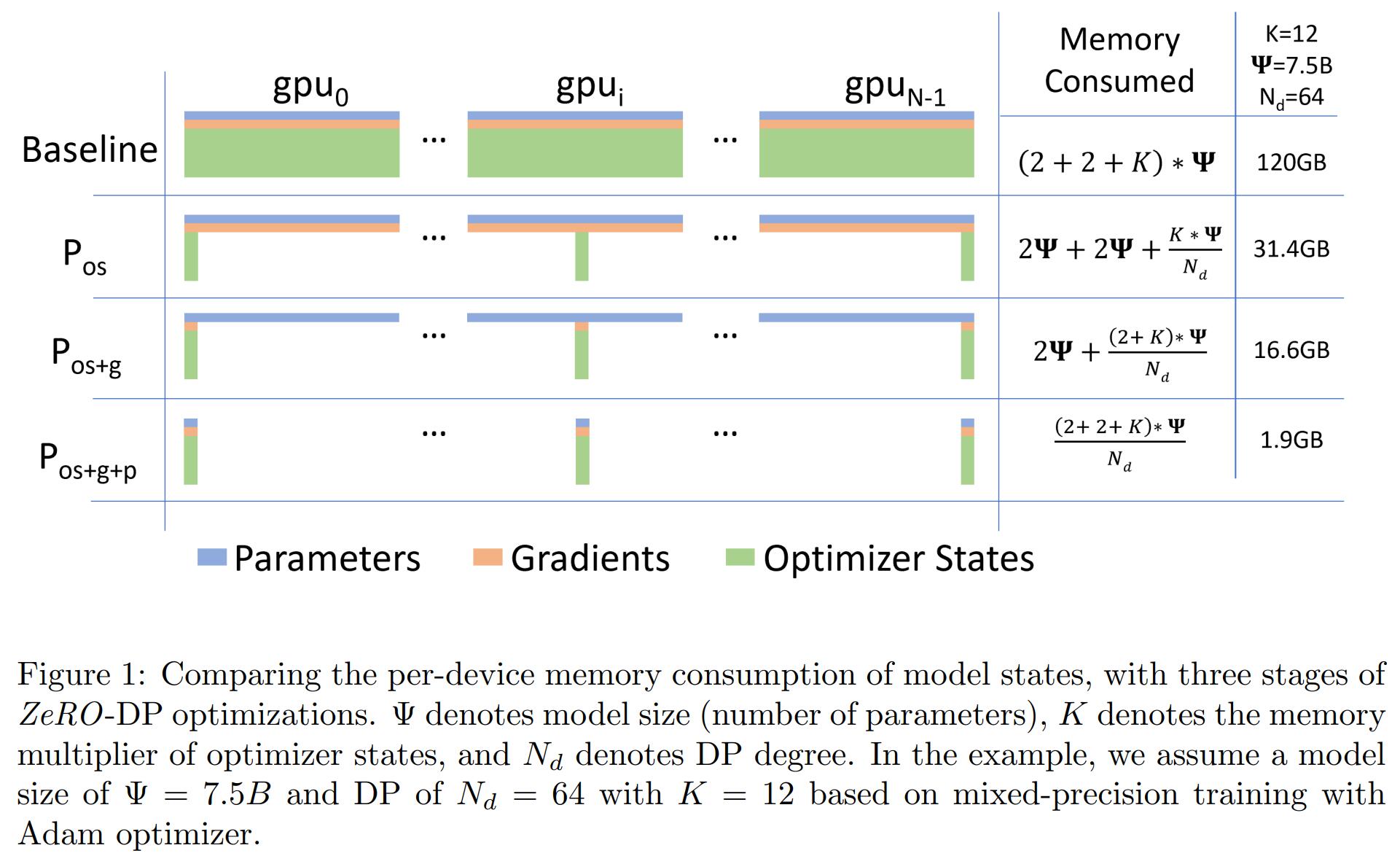
具体流程可参见 KDD 2020 中 Deep Speed 的 Tutorial,在视频的第 35 分钟开始,动画演示 ZeRO-DP 的三个 Stage 的过程。
ZeRO-R
在 ZeRO-DP 提高了模型状态的内存效率之后,激活、临时缓冲区、不可用内存碎片所消耗的剩余内存可能成为次级内存瓶颈,因此又提出了 ZeRO-R 对 Residual States 进行优化:
- 对于 activations (stored from forward pass in order to perform backward pass),ZeRO-R 通过 activation partitioning 来识别和删除�现有模型并行方法中的 activation 复制,且还会在适当的时候将 activation 卸载到 CPU 中。
- 为 temporary buffers 定义适当的大小以达到内存和计算效率的平衡。
- 由于不同张量生命周期的变化,在训练过程中会出现碎片化的内存,造成连续内存不足,从而导致内存分配的失败。ZeRO-R 根据张量的不同生命周期来主动管理内存,从而防止内存碎片化。
Reference
- Micikevicius, Paulius, et al. “Mixed precision training.” arXiv preprint arXiv:1710.03740 (2017).
- https://zhuanlan.zhihu.com/p/84219777
- Kingma, Diederik P., and Jimmy Ba. “Adam: A method for stochastic optimization.” arXiv preprint arXiv:1412.6980 (2014).
- https://www.youtube.com/watch?v=czgA-MbAdvA&t=2550s
异构训练
人们在努力研究如何更好地利用 GPU 的计算能力的同时,往往忽略了 CPU 内存通常比 GPU 内存具有更大的容量。例如,在配备 8 个 Tesla V100 GPU 的典型 Nvidia DGX1 工作站上,每个节点的聚合 GPU 内存为 256 GB,而 CPU 内存为 512 GB。如果 CPU 内存可用于模型训练,则可以简单地按比例放大模型大小。此外,由于 NVMe 固态硬盘 (SSD) 与传统硬盘 (HDD) 相比具有较高的通信带宽,因此 NVMe SSD 也可用于容纳模型数据,进一步提高单节点的训练能力。
DeepSpeed 提出了 ZeRO-offload,在不使用时将张量从 GPU 转移到 CPU 或 NVMe 磁盘上,以便为更大的模型腾出空间。通过利用高性能的异构存储设备,并在不同的硬件设备之间不断交换张量,可以在单个 GPU 上训练具有数十亿参数的模型。
ZeRO-offload
- Ren, Jie, et al. “ZeRO-Offload: Democratizing Billion-Scale Model Training.” USENIX Annual Technical Conference. 2021.
Data-Flow Graph
-
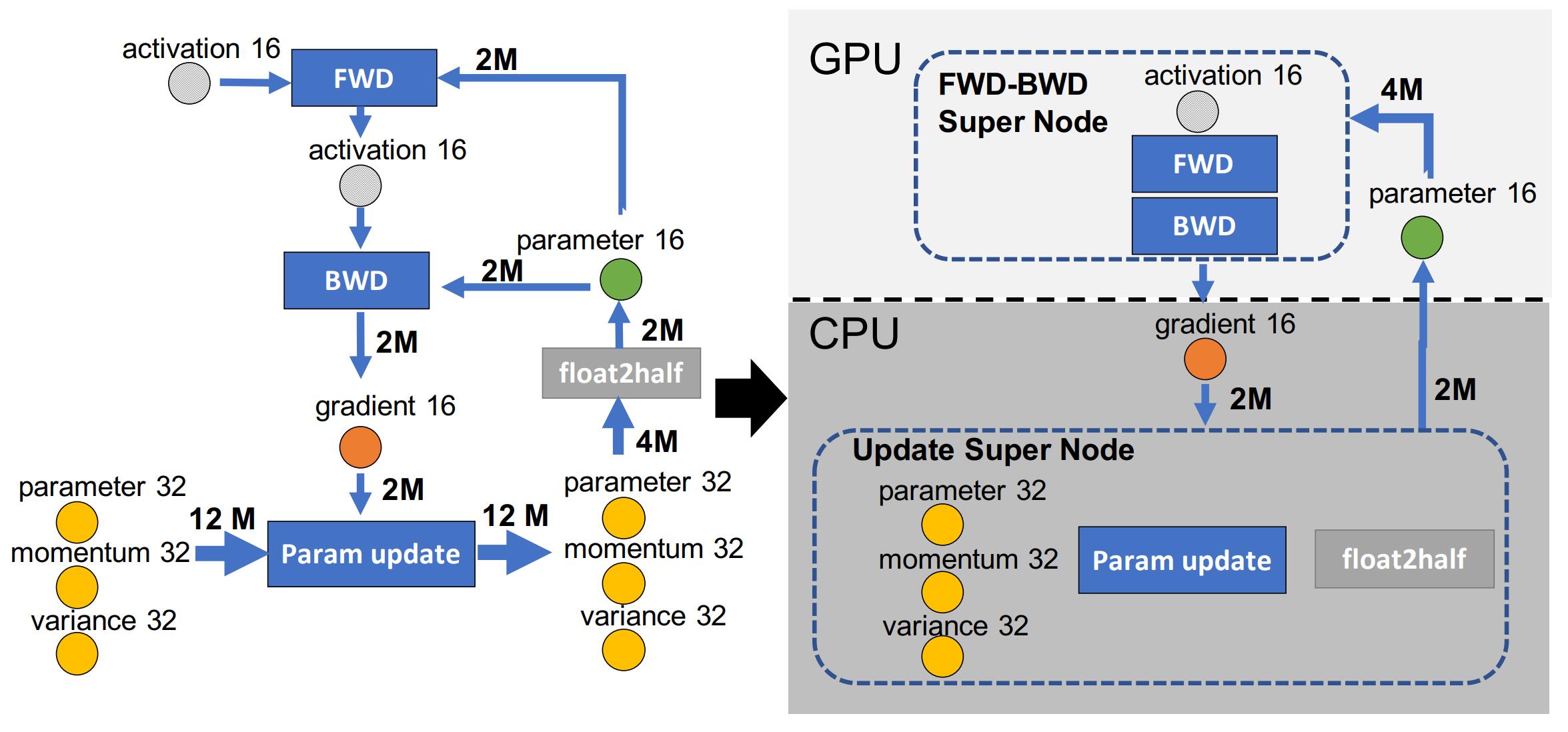
深度学习训练的工作负载可以表示为数据和计算的加权有向图,如下图所示,圆形节点表示模型状态(parameter16, gradient16, parameter32, momentum32, variance32),矩形节点表示计算(forward, backward, param update),图中的边表示节点之间的数据流,边的权重是在训练迭代期间流经它的总数据量(以字节为单位)。
-
offload 策略可以表示为对图的划分,将图划分为两个分区,分区中的计算节点、数据节点分别在拥有该分区的设备上执行、存储。GPU 和 CPU 之间所必须的总通信量由跨两个分区运行的边的权重给出。
-
划分的衡量指标:CPU 计算开销、通信开销、内存节省
限制 CPU 计算
给定模型大小,有效批量大小,则每次训练迭代的计算复杂度通常为,为了避免 CPU 计算成为性能瓶颈,只有那些复杂度低于的计算才应该被卸载到 CPU,因此具有复杂度的前向传播和反向传播必须在 GPU 上完成,而具有复杂度的其他计算(例如范数计算、权重更新等)可以卸载到 CPU 执行。基于此观察,可以将前向传播计算节点和后向传播计算节点合并为一个超级节点(FWD-BWD)并将其分配给 GPU。
最小化通信量
将前向和后向计算合并为一个超级节点后,图中的所有节点都是环路的一部分,对该图的任何分区策略都需要切割至少两条边,每条边的权重至少为 2M,因此任何模型状态卸载策略的最小通信量为 4M。
- fp32 超级节点:从图中可以看出,任何不将 fp32 模型状态与其生产者和消费者计算节点放在一起的分区策略都无法实现 4M 的最小通信量。这样的 partition 至少要切割一条边的权重为 4M,另一条边的权重至少为 2M,导致通信量至少为 6M。因此,为了实现最小通信量,必须将 fp32 模型状态与其生产者和消费者计算节点放在一起,可以将 fp32 状态节点(momentum32、variance32 和 parameter32)与 Param update 和 float2half 合并为一个超级节点(Update Super node)。
- p16 节点分配:除两个超级节点外,现在只剩下 p16 data node 和 g16 data node,为了实现最小通信量,p16 必须与 FWD-BWD Super 处于同一分区,因为这两个节点之间边的权重为 4M。
最大化内存节省
经过上述合并与分配,目前只剩 g16 和 Update Super 没被分配,由于无论怎么分配这两个节点,都能保证最小通信量,因此可以选择最大限度节省 GPU 内存的方案,即将 g16 和 Update Super 都分配给 CPU。
单 GPU 调度
ZeRO-Offload 可以在每个参数的梯度计算完成后,立即将这些梯度单独或分组传送到 CPU。因此,在梯度被转移到 CPU 内存之前,在 GPU 中只需少量内存来临时保存梯度。此外,梯度的传输与反向传播并行,也允许 ZeRO-Offload 隐藏很大一部分的通信成本。CPU 在更新参数时,也用相同的方法进行同步传输(图中的 p swap 那里应该是 CPU->GPU)。
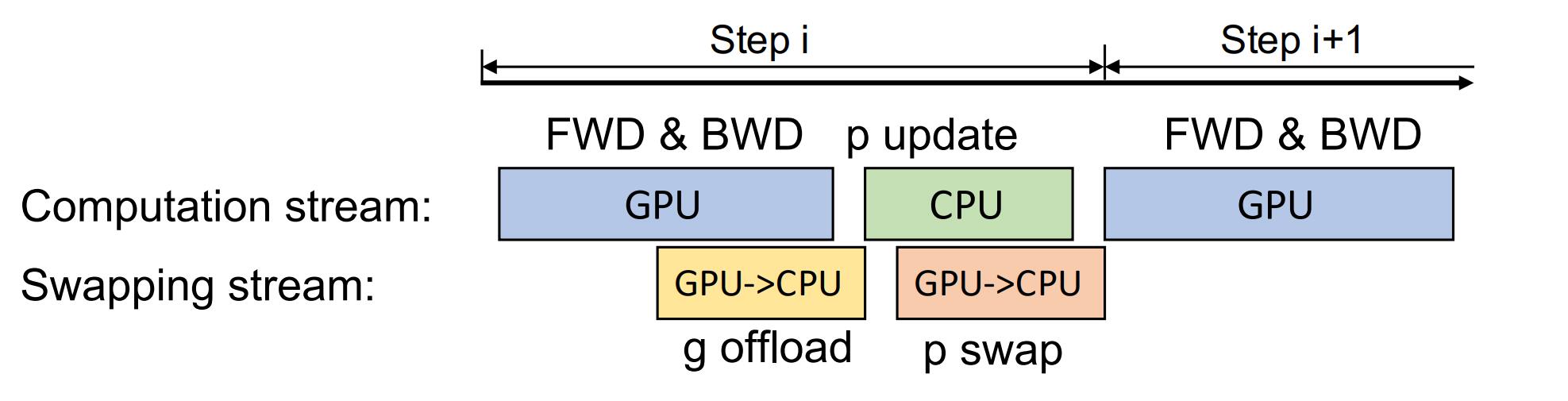
多 GPU 调度
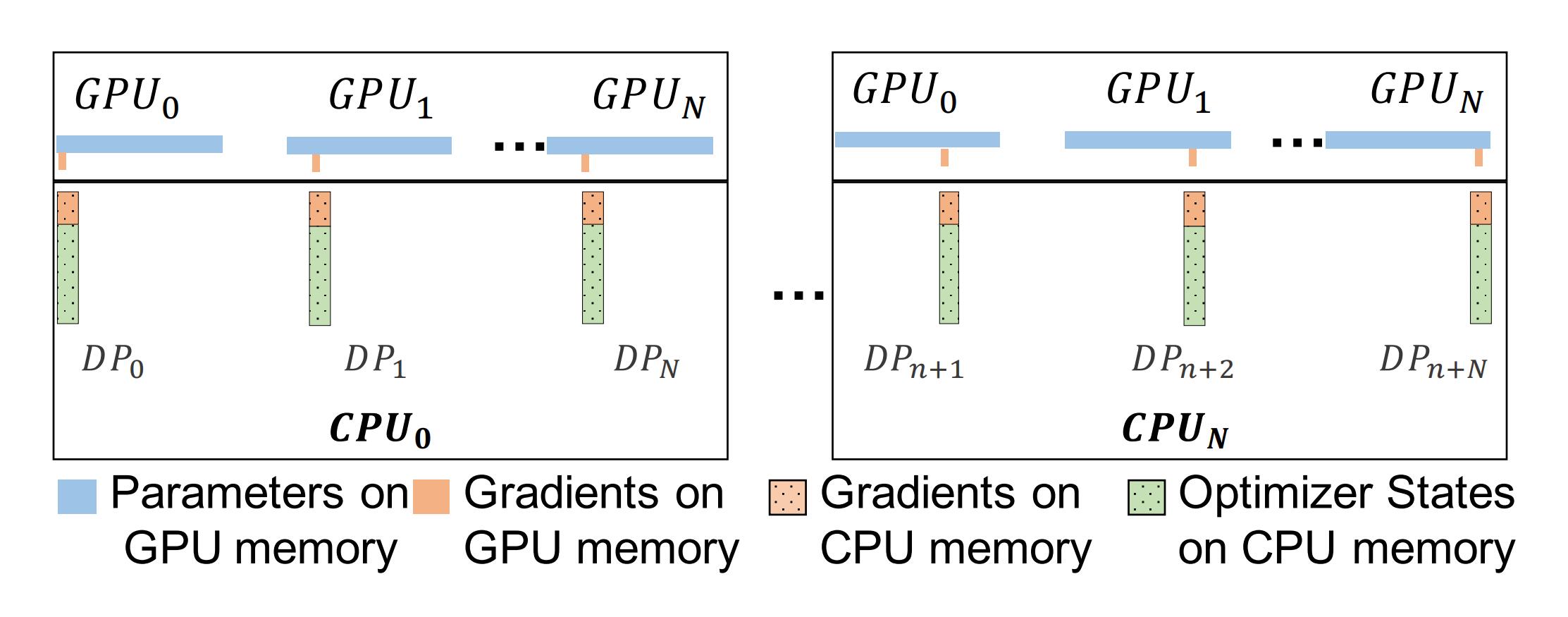
ZeRO Offload 保留了 ZeRO Stage-2 的分区策略(划分优化器状态和梯度),同时将分区后的梯度、优化器状态和相应的参数更新卸载到 CPU。
框架设计与实现
多维模型并行
Colossal-AI 提供了一些了模型并行方法以满足分布式训练的需要,包括 1D, 2D, 2.5D, 3D 张量并行、序列并行、流水线并行等,可以在大规模的计算集群中应用混合并行来加速模型训练。
增强的分片和卸载
在上文中��,我们介绍了 DeepSpeed 的 ZeRO 系列,但一些不必要的复杂实现降低了 DeepSpeed 的效率和可扩展性,Colossal-AI 重新设计了分片和卸载模块以获得更好的性能。对于零冗余数据并行训练,Colossal-AI 定义了一个统一的张量分片接口,支持定制化的分片策略,从而允许 model data 和 optimizer data 以松耦合的方式被分片。此外,训练流程也可以通过用户定义的 life-cycle hooks 来轻松修改。通过上述设计,Colossal-AI 不仅可以实现零冗余机制,还为不同粒度的更多优化提供了空间。
在 Colossal-AI 中,由于其可扩展设计,还集成了 PatrickStar 对内存空间所进行的优化。
Memory Space Reuse
在前向传播中,我们持有 fp16 参数,没有梯度。在后向传播中,fp16 参数被用来计算梯度,当梯度计算完毕后,就不再需要这些 fp16 参数了,那么我们就可以把 fp16 梯度保存在原来 fp16 参数的存储空间中,这个过程是以子模块的粒度流式传输的,可以进一步减少冗余和峰值内存使用。
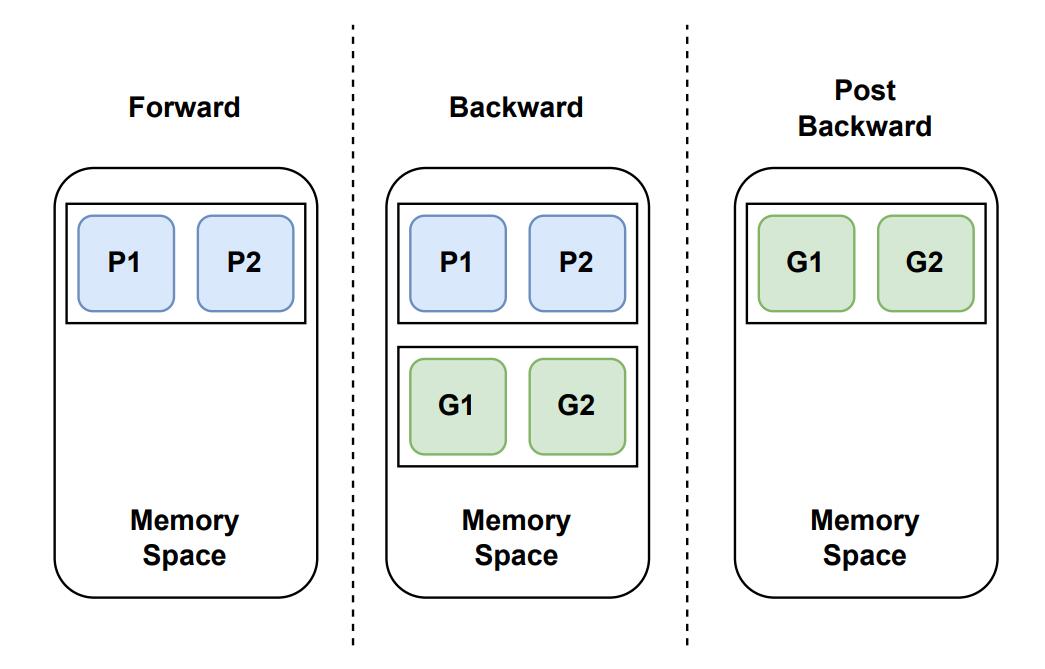
Adaptive Hybrid Adam Optimizer
当启用 ZeRO-offload 时,DeepSpeed 使用 CPU Adam Optimizer 进行优化操作,相比之下,Colossal-AI 使用 Hybrid Adam Optimizer 进行优化,其监控 GPU 上的可用内存,只要有剩余空间,它就会在 GPU 上保存部分参数和梯度,通过这种方式,参数在 CPU 和 GPU 上同时更新,从而降低了时间成本。
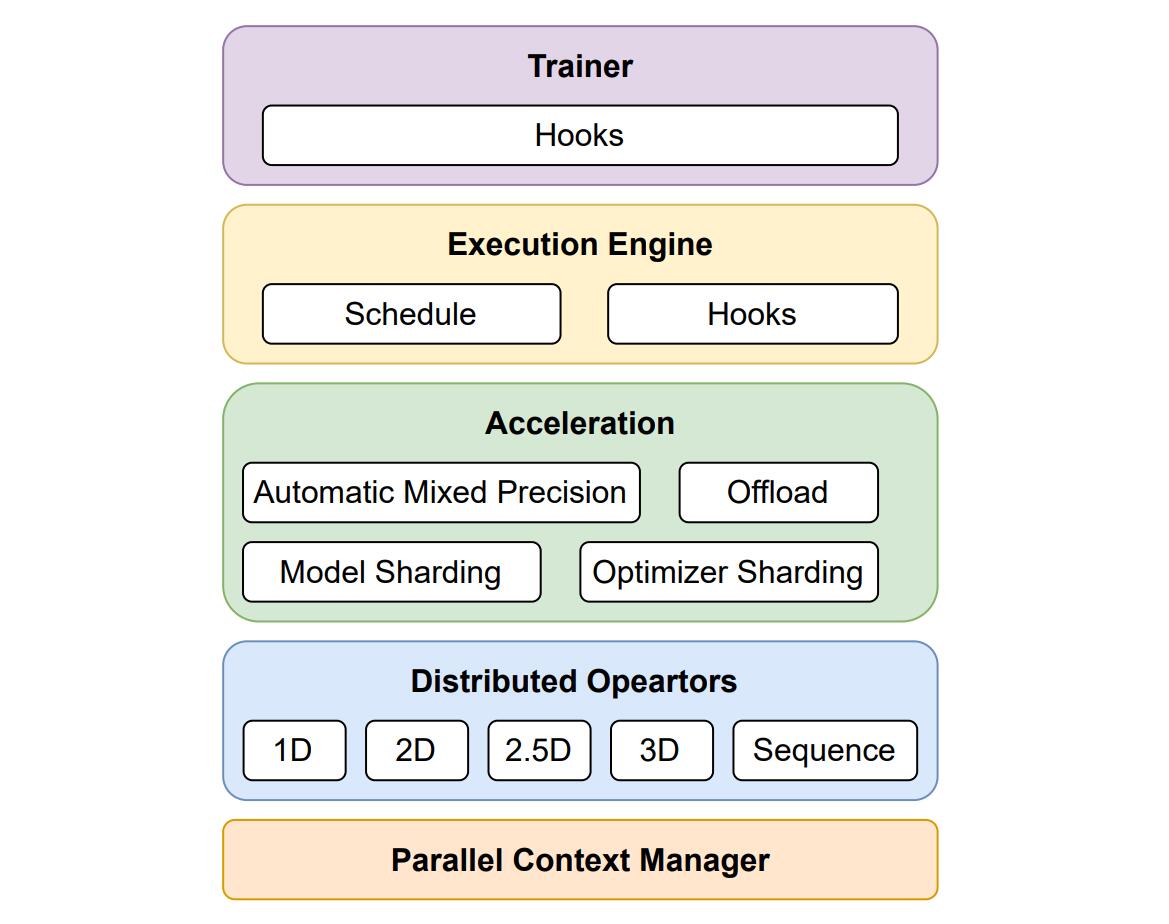
架构设计
Colossal-AI 的基本组件是 Parallel Context Manager,负责存储复杂的混合并行分布式环境的元信息,如分布式网络拓扑结构等。基于 Parallel Context,Distributed Opeartors 会自动切换到相应的并行模式,这样,复杂的计算和通信流程对用户透明�,用户可以很方便地构建并行模型。再上面一层是 Acceleration,包括自动混合精度训练、分片、卸载等优化工具。最后,Execution Engine 控制训练过程,Trainer 提高更高抽象层次的 API 以启动训练,系统还支持自定义 Hooks 来对训练流程进行修改,从而提高了可扩展性。